Abstract & Introduction
作者认为,人工标注 rationale成本高昂且模型性能不稳定,提出了一个**原理增强集成(rationale-augmented ensembles)**的方法
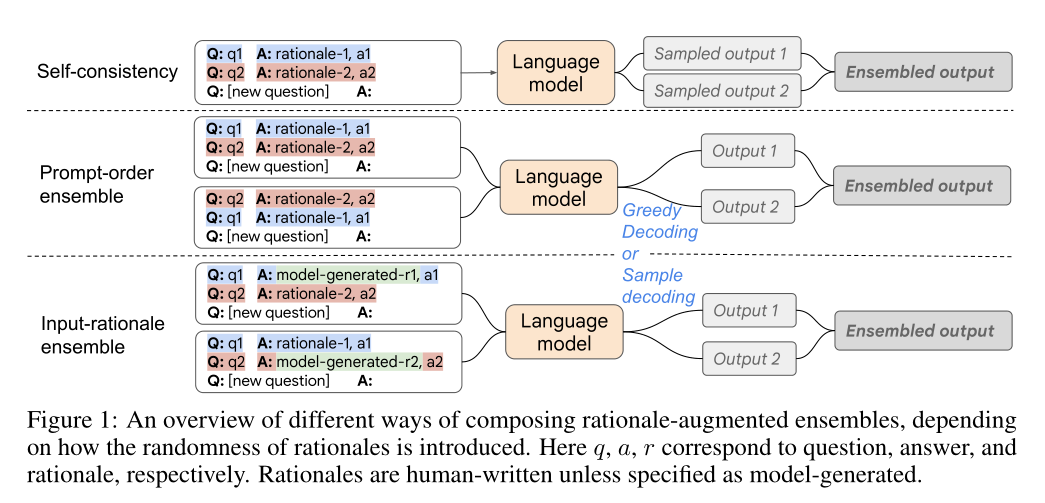
- 自一致性
- 样本顺序
- 手工标注+机器生成
原理增强集成框架的优势:
- 比先前工作提出的few-shot/zero-shot效果好
- 弥补了人类标注rationale导致下游任务表现不好的缺点
- 适用于NLP其他领域,即使这些领域不需要推理过程
作者尝试解释这两个问题:
- 为什么rationale ( 我认为rationale与chain of thought同义,可以表示[原理]或[思维链]的意思)在少样本学习中有效?
- 如何在NLP任务中使用可靠的rationale
Rationale-Augmented Ensembles in Language Models
探索了rationale对最终结果的敏感性程度;旨在降低敏感性改善最终性能为目标提出了rationale-augmented ensembles
Optimality of the rationales in few-shot learning.
作者在四个数据集上做了一个实验,给定4个人工标注的带rationale的样本。其中no-rationale表示不适用任何rationale,human-written表示完全使用rationale,sampled-rk表示第k个样本的rationale替换成机器生成的rationale。
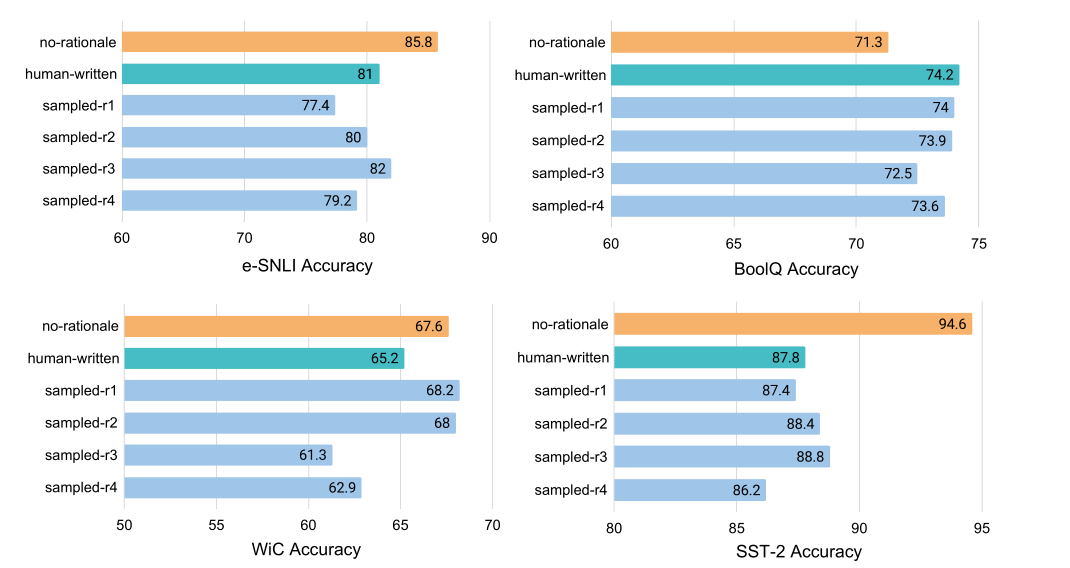
结果表示
- 不见得使用了rationale结果就一定会好
- 机器生成的rationale结果比人工标注的好(可能是机器世界和人类世界的“认知不一致”导致的)
Rationale-augmented ensembles

- Self-consistency自一致性:
- Prompt-order ensemble样本顺序
- Input-rationale ensemble手工标注+机器生成
Experiments Result
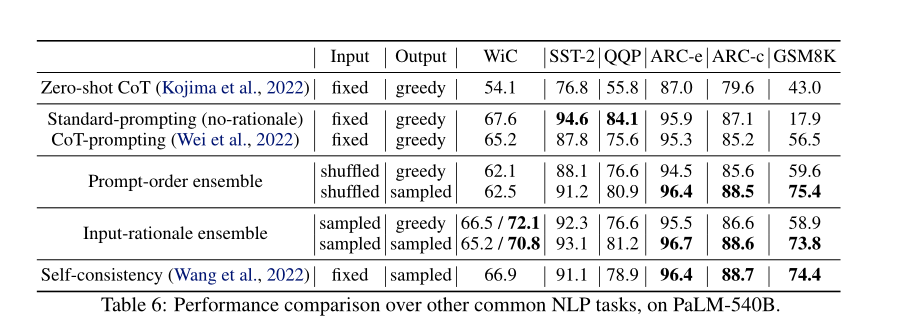
【不用推理的任务强行用推理会怎么样?】:有些无需推理步骤的任务如SST2和QQP,如果使用手工标注的样本则效果不好。如果使用rationale-augmented ensembles方法可以缩小这个差距
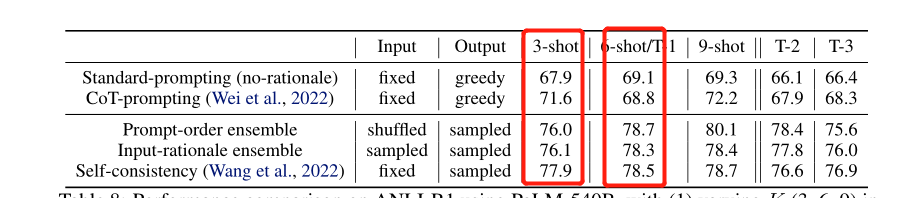
【K-shot learning中K的选择】选择K-shot中不同K的效果。虽然增加示例K的数量通常会提高性能,但基本原理增强的集成会有力地提高性能,超过标准和思想链,从而促进K的所有值。
【人工标注还是必要的】:尽管提议的框架减轻了对人工编写的理论的敏感性,但仍需要一些人工编写的种子理论,这仍可能会影响产出理论的生成。
一些想法
我认为rationale-augmented ensembles 是这样的模式:
- 人工标注M个样本,每一个样本包括 (Q, R, A)。然后让一个工具人来生成(Q, R^, A)。
- 对于即将给模型学习的K个样本会采用集成的方式根据QN得到结果RN^和AN^
- 第一种集成方式self-consistency:直接按照原定顺序学M个样本的(Q, R, A),然后给定新问题QN,生成若干个结果(RN, AN),用投票采样的方式采样答案(RN^, AN^)
- 第二种集成方式 Prompt-order ensemble:按照随机的顺序学M个样本的(Q, R, A),然后给定新问题QN,生成若干个结果(RN, AN),用投票采样的方式采样答案(RN^, AN^)
- 第三种集成方式 Input-rationale ensemble: 用采样的方式学习M个样本的(Q, R, A)或(Q, R^, A),然后给定新问题QN,生成若干个结果(RN, AN),用投票采样的方式采样答案(RN^, AN^)
在本文的实验中,有一个有趣的现象:机器生成的rationale在对比实验中比人工标注的好。可能是机器世界和人类世界的“认知不一致”导致的,也就是说在机器世界的空间里机器根据自身学习环境生成了rationale,也许人类不能理解rationale,但是机器的理解成本相对会低。