摘要
将幽默等级识别视为自然语言推理任务
将幽默文本划分为“铺垫”和“笑点”两个部分,分别对其语义和 语义关系进行建模,提出了一种多粒度语义交互理解网络,从单词和子句两个粒度捕获幽默文本中语义的关联和 交互。
在 Reddit公开幽默数据集上进行了实验,相比之前最优结果,模型在语料上的准确率提升了1.3%
相关工作
幽默理论
- 乖讹论。认为幽默是人类对不协调事 物的感知,当事物的发展违背人们的常识和期望时, 幽默就产生了
- 脚本语义理论 (ScriptSemanticTheoryofHumor,SSTH)。该理 论认为语义对立是幽默产生的重要原因。
- 基于以上幽默 理 论,Paulos 等[7]将 幽 默 分 为 “铺 垫”和 “笑 点”,认为两部分之间存在对立统一的关系。
幽默识别
- 机器学习方法
- Yang等[10]从不一致性、歧义性、语音特性和人 机交互特性四个方面提取幽默的语义特征,采用了随机森林方法识别幽默
- Barbieri等[11]根据幽默 问题的语音和歧义性特点,构造了多种幽默特征。
- Zhang等[3]基于幽默的语言学理论,构建50多种幽 默特征并将它们划分为五个类别。
- Liu等[12]提取了 对话中的情感特征及情感关联特征识别对话中的幽 默。
- 深度学习方法
- 杨勇等[14]从音、形、义三个维度对幽默特征 进行建模,采用层次注意力机制对幽默进行识别。
- Bertero等[15-16]由《生活大爆炸》中的文本和语音内 容构建幽默数据集,采用长短时记忆网络和卷积神 经网络自动抽取文本语义特征,从而预测对话中的 幽默。
- Baziotis等[17]利用注意力机制,更好地关注 到句子中的特定单词,从而提高了幽默识别的性能。
- 除了英文,研究者采用深度学习方 法对西班牙文[19]和俄文[4]语料进行了幽默识别。
- 机器学习方法
幽默等级识别(幽默等级识别使计算机能够理解哪些语义和语 义关系使句子更加有趣。)
- Westbury等[20]对单词的幽默程度建模并对4997个单词的幽默程度进行了 评分。
- Hossain等[6]通过**重新编辑新闻标题使其变 得更加幽默,**并对编辑前后文本语义的幽默程度进 行了分析。
- Cattle等[21]将文本划分为“铺垫”和“笑 点”两个部分,并指出二者的语义相关性对文本的幽 默等级具有显著影响。
作者提出的幽默等级识别方法
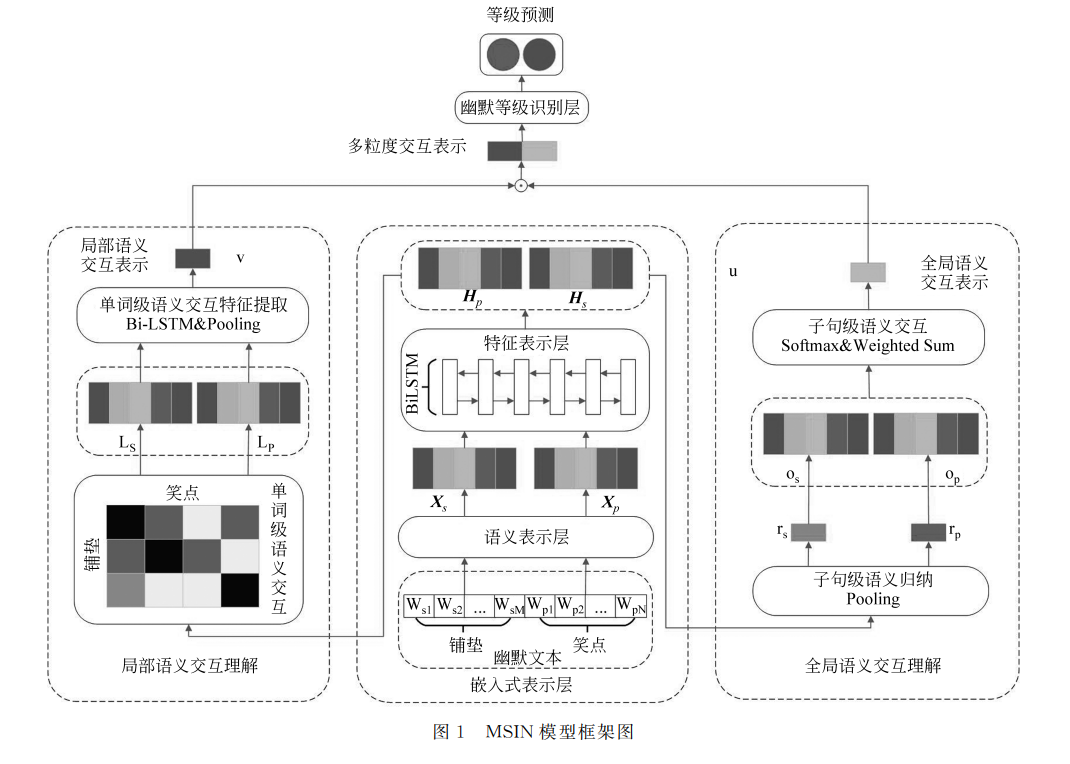
基于多粒度语义交互理解网络的幽默等级识别 方法主要包括两个层次:
语义的嵌入式表示层(中间)
- 目前还没有由幽默 语料训练得到的词嵌入表示,而大规模的词嵌入表 示,如 GloVe [24]、BERT [25]等,一般是利用通用语料 或者新闻语料训练得到的。直接采用单一的词嵌入 表示往往使得幽默等级识别的性能欠佳。
- “铺 垫”和“笑点”在幽默等级识别中发挥着不同的作用, 将二者统一建模,不利于文本的幽默等级识别。
- 因此,分别对“铺垫”和“笑点”进行建模,采用多个领域词嵌入(glove和Word2Vce)表示进行融合,并采用 Bi-LSTM 提取两个部分的高维语义特征。
交互语义特征提取层(左边 和 右边)
Engelthaler等[28]指 出不同单词在句子中表现出不同的幽默程度。单词 的语义信息与语句的幽默等级具有一定的相关性。因此,作者考虑对局部和全局语义做交互
局部语义交互理解模块
Yang等[10]研究发现,在幽默文本中,不同词语 的重要程度不同,当删除幽默文本中的某些词语后, 文本的幽默程度下降,甚至完全消失。所以,作者认为探究局部的语义是有意义的
attention(语义交互) + BiLSTM + pooling生成4个向量,然后concat起来作为v
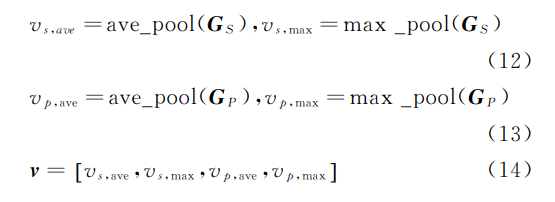
全局语义交互理解模块
- Ma 等[29]研究表明,对于文本中的不同语义单 元,其单词的含义会受到其他语义单元的影响。“铺 垫”和“笑点”作为幽默文本的两个子句级语义单元, 二者互相作用,对幽默等级识别产生重要影响。
- pooling得到分别得到两个表示句子的向量,然后进行attention交互,最后拼接成u向量
实验
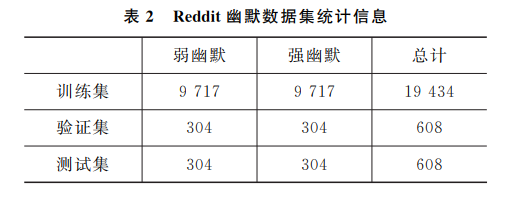
数据集
- Reddit数据集
- 评价指标:为了便于和基线方法进行比较,本 文采用了被广泛接受并应用于文本分类任务中的精 确率(Acc)、准 确 率 (P)、查 全 率 (R)和 F1Score (F1)作为评价指标。
实验结果
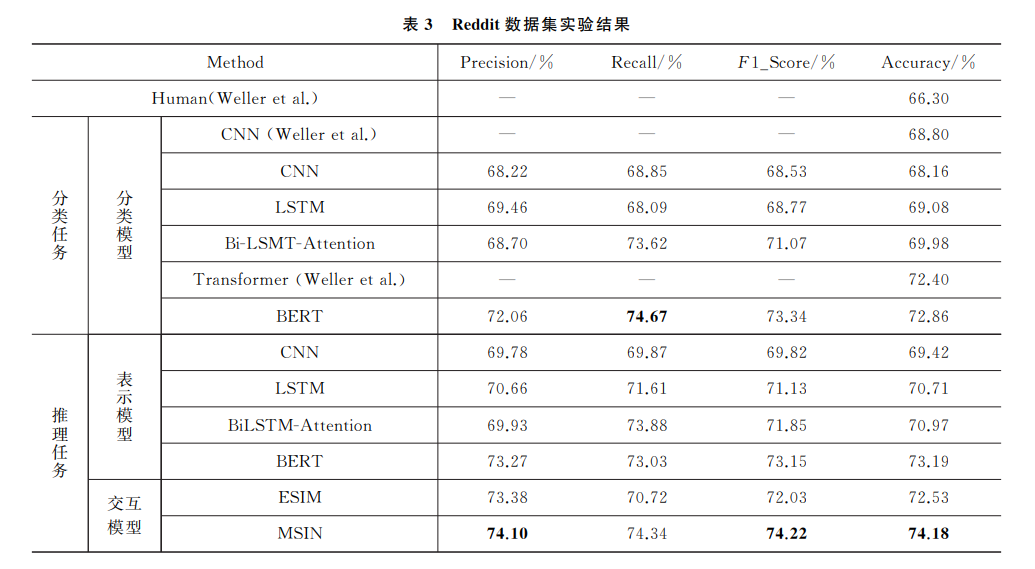
作者提出的MSIN模型在三个指标上表现非常棒
消融实验