Abstract & Introduction
ABSA是一个细粒度的情感分析任务,要求我们检测句子在某一方面是否有情感极性,以及对应的极性。
作者表示可以将[方面]分成两类:
- explicit aspect-term:很明显出现在句子中(占比较少,处理起来简单)
- implicit aspect-category: 通过一些指示词隐式表示(占比很多,处理起来困难)

介绍了以前处理ABSA的方法
- 基于句法信息转化器、n-grams和情感词典,来辅助分类器(贝叶斯或SVM)完成。(但是这样做只能处理explicit aspect)
- 常规的微调预训练模型
- Prompt的方式,将ABSA任务转化成QA辅助句,其中Q是原文,A是对方面情感的描述疑问。(这种做法需要大量的有标签数据,可以参考论文)
作者提出了一种统一的框架来处理方面分类和方面情感分析子任务,叫做BERT-based Auxiliary Sentence Construct-ing (BERT-ASC)
使用L-LDA为每一个[方面]提取一组[种子]集合
- Aspect: food — Seed:{meal, bread, rice}
- 如何做呢?由于BERT模型的预训练会使得相似的词在向量空间中的距离尽可能小。所以可以根据方面词在向量空间某个范围的词向量作为种子集合
根据[方面]和[种子]来构造辅助句子提供个体PLM来微调
使用构造的辅助句子来微调,可以让BERT学习到[特定于方面的表示]而不是[方面本身]
The proposed solution
Task Description
Please click this link to see the description of TABSA and ABSA task.
Aspect Seed Extraction
使用L-LDA来为每一个方面抽取一组 “方面种子”,详见下图

Auxiliary-Sentence Construction
Semantic candidates(语义候选词,方面的映射)
- 由于BERT在预训练的后语义相似的词在语义空间内的特征向量是相近的,因此考虑将 原文中的每一个单词和”种子词”进行相似度计算,若超过某个阈值(如0.8)则加入“语义候选词集合”。
- 如果上述操作完成后“语义候选词集合”的大小为0,则用方面本身来当作“语义候选词”
Syntactic information(语法信息,方面的观点词)
- 利用句法信息(依赖关系树)来提取“语义候选词”的“意见词” 。
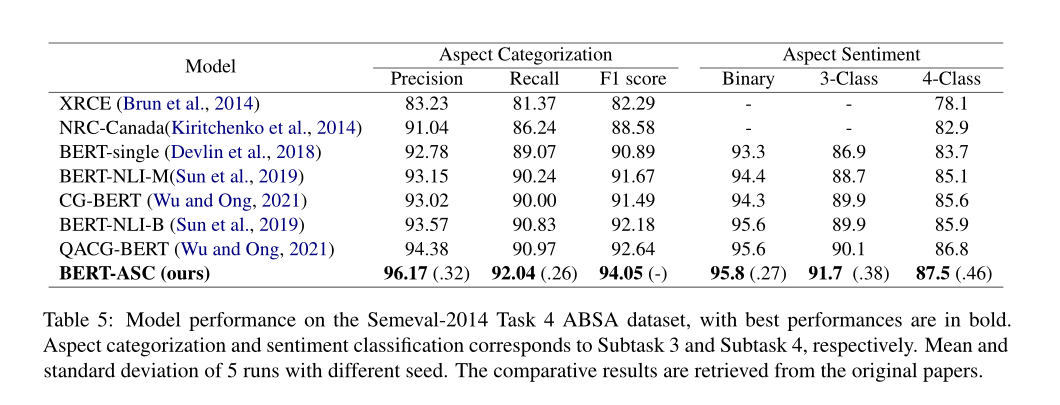
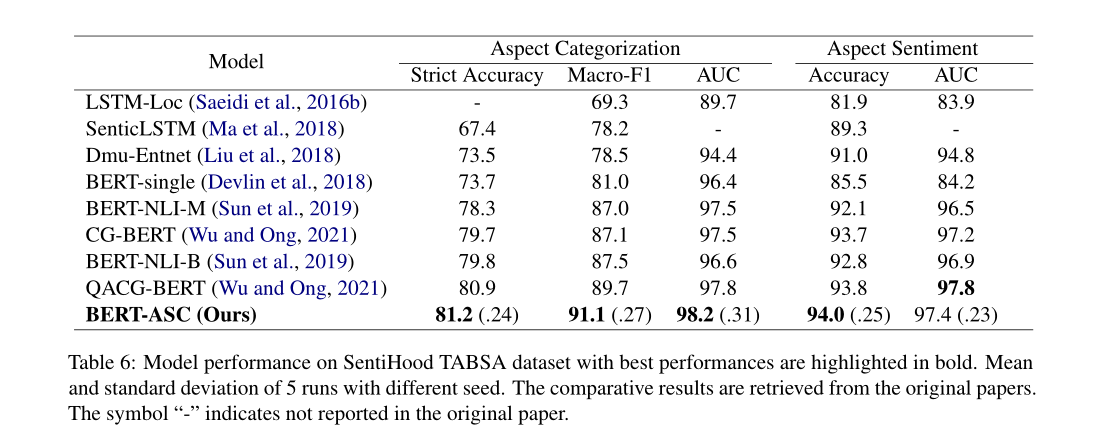
Experiments