背景
预先训练的语言模型编码了不受欢迎的社会偏见,这种偏见在下游使用中进一步加剧。为此,作者提出了MABEL(一种使用纠缠标签减轻性别偏见的方法),这是一种减轻情境化表达中性别偏见的中间预训练方法。我们方法的关键是在自然语言推理(NLI)数据集的反事实增强、性别平衡的蕴涵对上使用对比学习目标。
一言以蔽之,MABEL通过对预训练数据库中的所有带有敏感属性的词进行反义替换,其他词则保持不变,然后进行对比学习来消除偏见。
细节
具体来说,研究团队做了两方面的工作。
首先是数据集方面,研究团队使用的是自然语言推理(NLI)数据集,它在训练有区别性和高质量的句子表征方面特别有效。
由于研究团队主攻性别歧视方向的偏见,因此,他们从NLI数据集中提取了在前提或者假设中包含性别术语的所有隐含对。
然后对数据进行**反事实增强 (counterfactual data augmentation)**,即将数据集中包含性别敏感的词汇全部替换成反义词汇,如男生→女生…
接下来的步骤就比较关键了:训练!
训练主要针对的是以下三个损失函数:
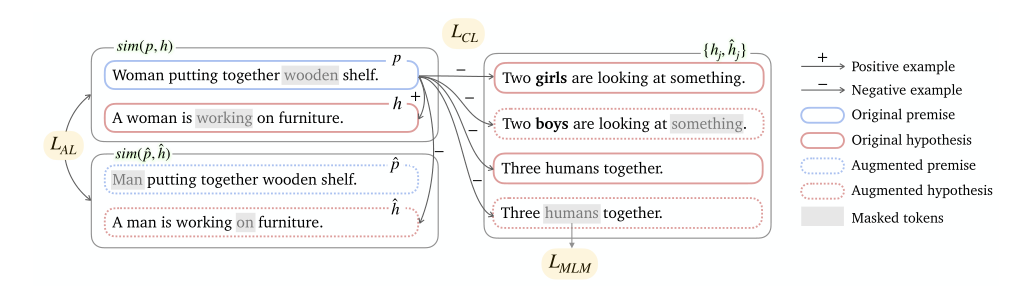
contrastive loss based on entailment pairs
第一个,对比度损失的训练会产生一个更加各向同性的表示空间,其中句子的几何位置可以更好地与其语义对齐。

their augmentations, an alignment loss
第二个是对齐损失 (Alignment loss),这就比较好理解了,它是用来表示原始隐含对和其增强对之间的内部关联。
也就是说,这个函数能够使模型最后生成的结果在男女之间更加平衡,以保证最后模型生成的结果性别歧视降到最低。
optional masked language modeling loss
第三个是掩码语言模型损失 (Masked language modeling loss),这是最后额外附加的一个损失,目的是为了保持模型的语言建模能力。
最终总损失如下:

实验
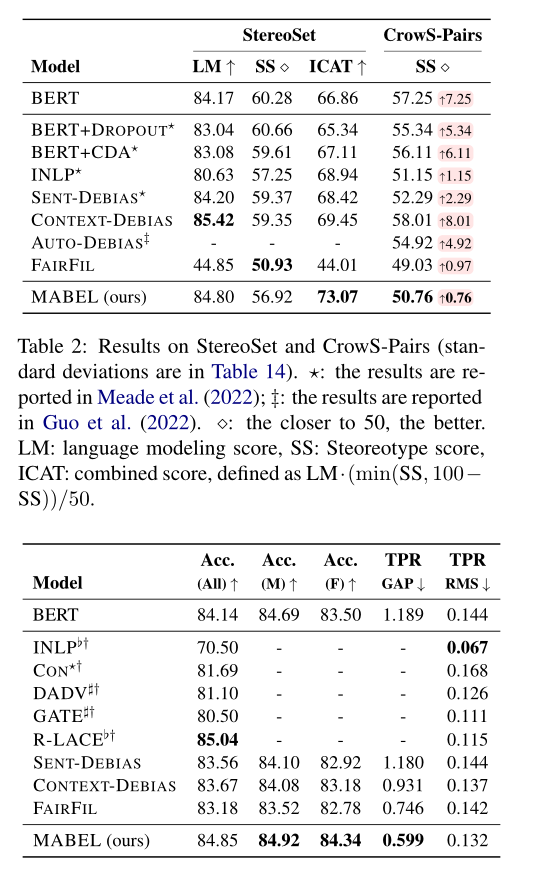
讲了这么多,那MABEL这个方法偏见消除的效果如何?
MABEL表现出了良好的公平性-性能权衡。
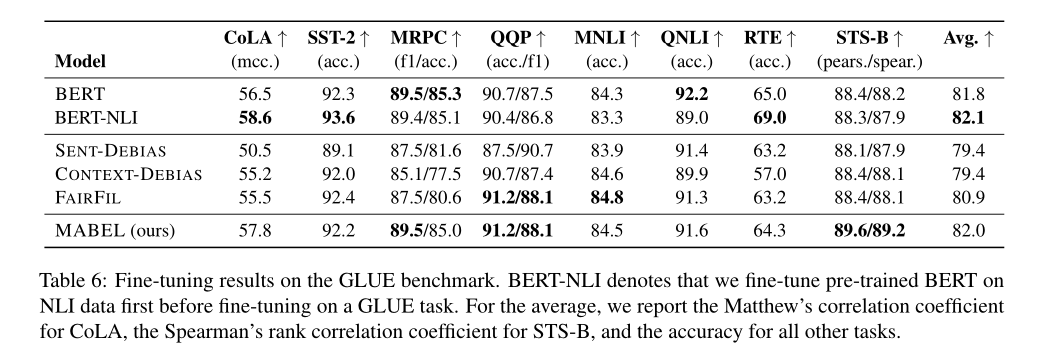
此外,研究团队还评估了语言模型在使用了消除性别歧视的方法后是否仍然保持一般的语言理解,结果显示模型能够很好地保留其在GLUE上的自然语言理解(NLU)能力。
一些想法
从这篇paper中收获了一些idea用于SemEval2023-task10女性性别歧视文本检测竞赛
- 初步使用本文提出的模型”princeton-nlp/mabel-bert-large-uncased” 套到该竞赛上,发现效果奇差无比。一个直观的解释是假如模型已去除性别偏见,那么遇到带有女性歧视的文本时模型会将其视作正常文本。反其道而行之,我们可以**训练一个 “带有性别歧视偏见的模型”**,那么模型也许遇到厌女文本就会相对比较敏感,从而提高分类性能。
- 考虑到正例是针对女性的性别歧视文本,那么大部分样本带有女性的词汇(如:woman, girl, bitch…)。我们可以通过反事实增强构造相应的负例文本。